
A Carnegie Mellon team is uncovering important clues to the way that humans store and process language
As Tom Mitchell recalls it, the idea that led to the first crack in the brain's code was more a matter of desperation than inspiration.
Mitchell, chair of the Machine Learning Department, had been collaborating for years with cognitive neuroscientist Marcel Just, using machine learning techniques to make sense of the complex brain images produced by functional magnetic resonance imaging, or fMRI. These scans highlight areas of increased blood flow in the brain, signaling which neurons are activated in response to a stimulus, such as a word or picture.
For Mitchell and Just, these images provided a fascinating glimpse into the brain's inner workings. Each word or photo caused neurons scattered across the brain to fire, and the brain regions containing these neurons were identified in the fMRI scans. Algorithms and models developed by Mitchell and his students learned to identify these three-dimensional patterns and match them to a given word.
It was all very tantalizing for the researchers, who want to understand how the brain encodes meaning and perhaps find a way to identify what a person is thinking--in other words, "mind reading." But placing people inside the noisy, doughnut-shaped superconducting magnet of the fMRI scanner and asking them to repeatedly concentrate on one word at a time is laborious, expensive, and time-consuming. To develop a theory of how meaning is represented in the brain, they needed to move beyond the classifications they had developed for cataloguing fMRI patterns and find a way to accurately predict the activation patterns for actual words used in everyday speech--dozens, hundreds, even thousands of them.
"What we really needed," says Mitchell, the Fredkin Professor of Artificial Intelligence and Machine Learning, "was a computer-manipulable representation of meaning." Adding this intermediate layer of analysis would allow the computer to probe the images in ways no human could, breaking them down into component parts associated with each aspect of a word's meaning.
This resource was desperately needed, but Mitchell knew where to find it, thanks to his other major research interest--teaching computers to extract information from the Internet. He knew computational linguists had long wrestled with meaning and developed a number of ways of semantically representing words.
"So solving our problem," a smiling Mitchell says, tongue in cheek, "was just a matter of stealing that idea."
The technique that Mitchell and his cohorts borrowed for their study is called "corpus co-occurrence." This statistically driven technique infers the meaning of words by analyzing a gargantuan amount of text, called a corpus--in this case, Google text files totaling more than a trillion words that reflect typical English-language sentences. The meaning of each word is determined by examining which other words most often appear near it within the text corpus.
Unfortunately, that's not likely to be the way the brain determines the meanings of words, notes Kai-Min Chang, a graduate student in the Language Technologies Institute who began working with Mitchell and Just two years ago. "The corpus is huge," he says. "The word 'hammer' alone might be associated with thousands of words. You can't imagine the brain storing all of that. Humans probably use a system that is more concise."
But corpus co-occurrences proved to be a critical tool for exploring how humans encode the meaning of concrete nouns--names for things that you can see, hear, feel, taste, or smell. For this study, Mitchell chose 25 verbs associated with sensory-motor functions, such as "lift," "listen," "taste," "eat," "push," and "drive," and used their co-occurrences to encode the meaning of all concrete nouns in the corpus.
Meanwhile, Just and his students enrolled nine volunteers to sit inside an MRI machine in the Brain Imaging Research Center (BIRC) on Pittsburgh's South Side as they concentrated on a series of 60 stimulus nouns--five words in each of 12 semantic categories including animals, body parts, buildings, clothing, insects, vehicles, and vegetables. Each person lay on his or her back inside the magnet, staring at a mirror above them. The mirror reflected the words and pictures from a computer monitor, which was located safely beyond the most powerful portion of the machine's magnetic field. As the subject concentrated on each word, the machine made note of which areas of the brain were placing the largest demands on blood flow.
During the scans, the BIRC staff members saw nothing that would give them a hint about what the participants were thinking. The additional processing necessary to turn the weak electromagnetic signals emitted by oxygen nuclei in the blood into fMRI images didn't occur until after the raw data was uploaded into computers back on the Carnegie Mellon campus. That's when the real fun began.
The fMRI scans are much less detailed than MRI scans. Instead of two-dimensional pixels, they're composed of three-dimensional "voxels," each representing an area 3 millimeters by 3 millimeters by 6 millimeters. (By comparison, coarse grains of sand are 2 millimeters or smaller along each edge.) An fMRI scan comprises about 20,000 voxels. For each of the 60 stimulus words used in the experiment, an algorithm automatically determined how each co-occurrence of that word with one of the 25 sensory-motor verbs affected the activation of each of the voxels in the scans.
With this information in hand, the computer model the researchers developed could predict the activation pattern for any concrete noun in the corpus simply by knowing the frequency with which that noun co-occurred with one of the 25 verbs.
"You can think of these as little Lego bricks that you piece together," says Just, the D.O. Hebb Professor of Psychology in the College of Humanities and Social Sciences, who directs Carnegie Mellon's Center for Cognitive Brain Imaging. The word "celery," for instance, appears most frequently in the corpus with the verb "eat"; often, but less frequently with "taste"; a bit less with "fill," and so forth. Proportionally adding these individual activations together produced the predicted activation pattern for "celery."
To test this idea, the researchers used 58 of the 60 stimulus words to train their computer model and then used the model to predict the activation patterns for the remaining two stimulus words. When they compared the predictions with the actual activation patterns for those two words, the model had a mean accuracy of 77 percent.
The method proved powerful even when predicting activation patterns in semantic areas for which the model was untrained. For example, the model could be retrained with words from all but two of the 12 semantic categories; when tested with nouns such as "airplane" or "celery" from the excluded categories of vehicles and vegetables, the mean accuracy was 70 percent. That wasn't quite as good as when the model was tested with words from the categories the model was trained to handle, but still significantly higher than chance.
To test the model's ability to distinguish among a diverse set of words, they retrained it using 59 of the 60 stimulus words. They then presented the model with the fMRI of the withheld word and a list of 1,000 frequently used words from the corpus, plus the withheld word. The model predicted the fMRI image for all 1,001 words and compared those predictions to the actual fMRI of the withheld word, ranking them in order of similarity. Left to chance, the correct word would score a percentile rank of 0.50; in the research team's model, the mean rank was 0.72. The findings proved powerful enough to merit publication in the May 30, 2008 issue of the journal Science.
"We believe we have identified a number of the basic building blocks that the brain uses to represent meaning," Mitchell says.
Though corpus co-occurrences may not reflect the same methods used by the brain to represent meaning, the study yielded new insights into the nature of human thought. "Before these experiments, nobody knew how meaning would be represented in the brain," Just says. But as he and Mitchell studied the scans, they noted that the voxels that were activated often corresponded with areas of the brain associated with the senses or motor control. That suggests that the biology of the brain drives the way that meanings are stored and represented.
"We are fundamentally perceivers and actors," Just says. "So the brain represents the meaning of a concrete noun in areas of the brain associated with how people sense it or manipulate it. The meaning of an apple, for instance, is represented in brain areas responsible for tasting, for smelling, for chewing. An apple is what you do with it. Our work is a small but important step in breaking the brain's code."
Though the work might someday be useful for so-called "mind reading," Just says it could also provide meaningful tools for analyzing autism and thought disorders such as paranoid schizophrenia. It might also be useful in studying semantic disorders such as Pick's disease, a rare form of dementia with symptoms that can include difficulty in finding words and maintaining a conversation.
Mitchell and Just already are planning to expand their research to include fMRIs for phrases, short sentences, and combinations of words, such as "hungry rabbit" and "running rabbit." Likewise, they want to study how the brain processes abstract concepts such as "democracy," "science," and "justice." Rebecca Hutchinson, a Ph.D. student in computer science who has been working on the neurosemantics project since 2002, is already refining techniques that will help researchers sort out these more complex signals. Researchers will have to deal with uncertainty as to when the activation pattern for one word ends and the pattern for the next word begins. One possible solution is a new class of probabilistic models, called Hidden Process Models, that she and her colleagues developed for analyzing time-series data.
But even for single concrete nouns, "the Science paper is still just a start," says Chang, one of the report's co-authors. The 25 verbs chosen by Mitchell aren't necessarily the optimal set for revealing how the mind encodes meaning; a different set of verbs might work better, or perhaps a larger or even smaller number would be preferable. "Sometimes more is better, but not always," Chang says, noting that too large a set may result in a model that is too specific for a certain subset of subjects and thus limited in its "generalizability"--the ability to make the same predictions using other data sets.
Indra Rustandi, a Ph.D. student in computer science who has worked with Mitchell since 2003, is looking into algorithms that can automatically discover the best representation of the data. For instance, rather than selecting 25 verbs in advance to analyze the corpus, certain algorithms might figure out a set of words that will give the best prediction accuracy. Chang, whose study of semantics is part of his long-term goal to develop a computational model of language processing in the human brain, is also exploring ways to analyze fMRI scans that don't involve corpus co-occurrences. One possibility is based on feature-norming studies in psychology, in which people list the distinguishing characteristics of things. A combination of different semantic layers likely will be necessary to improve prediction accuracy, he says.
For Mitchell, this new insight into the function of the human brain presents an opportunity for computer scientists to reconsider some of their architectures. "One of the main problems in artificial intelligence is (deciding) how robots should represent the myriad things they see in the world," he says.
The human brain could store information about the word "tomatoes" much like a dictionary would, lodging it in the frontal cortex where higher reasoning takes place. Instead, the brain seems to use its sensory and motor sections to store the bulk of this information. Doing so may help the brain operate more efficiently, allowing it to make inferences about what it sees and reason about how to act on that information in the same areas of the brain where perception takes place.
"That's very different than how it's done in robots today," Mitchell says. "Maybe there's a reason the brain does it that way and maybe we should give that a little thought."
About the Photos:
At top, Marcel Just,director of Carnegie Mellon's Center for Cognitive Brain Imaging, and Tom Mitchell, head of the Machine Learning Department.
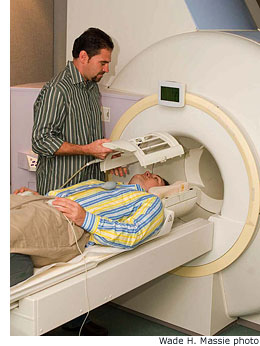
Second photo: Robert Mason, senior research associate at the Brain Imaging Research Center, a joint project of Carnegie Mellon and the University of Pittsburgh, demonstrates its functional magnetic resonance imaging (fMRI) scanner with the help of research coordinator Justin Abernethy. Using fMRI scans, computer scientist Tom Mitchell and cognitive neuroscientist Marcel Just have developed a model for predicting how different words activate different thought centers in the brain.
As Tom Mitchell recalls it, the idea that led to the first crack in the brain's code was more a matter of desperation than inspiration.
Mitchell, chair of the Machine Learning Department, had been collaborating for years with cognitive neuroscientist Marcel Just, using machine learning techniques to make sense of the complex brain images produced by functional magnetic resonance imaging, or fMRI. These scans highlight areas of increased blood flow in the brain, signaling which neurons are activated in response to a stimulus, such as a word or picture.
For Mitchell and Just, these images provided a fascinating glimpse into the brain's inner workings. Each word or photo caused neurons scattered across the brain to fire, and the brain regions containing these neurons were identified in the fMRI scans. Algorithms and models developed by Mitchell and his students learned to identify these three-dimensional patterns and match them to a given word.
It was all very tantalizing for the researchers, who want to understand how the brain encodes meaning and perhaps find a way to identify what a person is thinking--in other words, "mind reading." But placing people inside the noisy, doughnut-shaped superconducting magnet of the fMRI scanner and asking them to repeatedly concentrate on one word at a time is laborious, expensive, and time-consuming. To develop a theory of how meaning is represented in the brain, they needed to move beyond the classifications they had developed for cataloguing fMRI patterns and find a way to accurately predict the activation patterns for actual words used in everyday speech--dozens, hundreds, even thousands of them.
"What we really needed," says Mitchell, the Fredkin Professor of Artificial Intelligence and Machine Learning, "was a computer-manipulable representation of meaning." Adding this intermediate layer of analysis would allow the computer to probe the images in ways no human could, breaking them down into component parts associated with each aspect of a word's meaning.
This resource was desperately needed, but Mitchell knew where to find it, thanks to his other major research interest--teaching computers to extract information from the Internet. He knew computational linguists had long wrestled with meaning and developed a number of ways of semantically representing words.
"So solving our problem," a smiling Mitchell says, tongue in cheek, "was just a matter of stealing that idea."
The technique that Mitchell and his cohorts borrowed for their study is called "corpus co-occurrence." This statistically driven technique infers the meaning of words by analyzing a gargantuan amount of text, called a corpus--in this case, Google text files totaling more than a trillion words that reflect typical English-language sentences. The meaning of each word is determined by examining which other words most often appear near it within the text corpus.
Unfortunately, that's not likely to be the way the brain determines the meanings of words, notes Kai-Min Chang, a graduate student in the Language Technologies Institute who began working with Mitchell and Just two years ago. "The corpus is huge," he says. "The word 'hammer' alone might be associated with thousands of words. You can't imagine the brain storing all of that. Humans probably use a system that is more concise."
But corpus co-occurrences proved to be a critical tool for exploring how humans encode the meaning of concrete nouns--names for things that you can see, hear, feel, taste, or smell. For this study, Mitchell chose 25 verbs associated with sensory-motor functions, such as "lift," "listen," "taste," "eat," "push," and "drive," and used their co-occurrences to encode the meaning of all concrete nouns in the corpus.
Meanwhile, Just and his students enrolled nine volunteers to sit inside an MRI machine in the Brain Imaging Research Center (BIRC) on Pittsburgh's South Side as they concentrated on a series of 60 stimulus nouns--five words in each of 12 semantic categories including animals, body parts, buildings, clothing, insects, vehicles, and vegetables. Each person lay on his or her back inside the magnet, staring at a mirror above them. The mirror reflected the words and pictures from a computer monitor, which was located safely beyond the most powerful portion of the machine's magnetic field. As the subject concentrated on each word, the machine made note of which areas of the brain were placing the largest demands on blood flow.
During the scans, the BIRC staff members saw nothing that would give them a hint about what the participants were thinking. The additional processing necessary to turn the weak electromagnetic signals emitted by oxygen nuclei in the blood into fMRI images didn't occur until after the raw data was uploaded into computers back on the Carnegie Mellon campus. That's when the real fun began.
The fMRI scans are much less detailed than MRI scans. Instead of two-dimensional pixels, they're composed of three-dimensional "voxels," each representing an area 3 millimeters by 3 millimeters by 6 millimeters. (By comparison, coarse grains of sand are 2 millimeters or smaller along each edge.) An fMRI scan comprises about 20,000 voxels. For each of the 60 stimulus words used in the experiment, an algorithm automatically determined how each co-occurrence of that word with one of the 25 sensory-motor verbs affected the activation of each of the voxels in the scans.
With this information in hand, the computer model the researchers developed could predict the activation pattern for any concrete noun in the corpus simply by knowing the frequency with which that noun co-occurred with one of the 25 verbs.
"You can think of these as little Lego bricks that you piece together," says Just, the D.O. Hebb Professor of Psychology in the College of Humanities and Social Sciences, who directs Carnegie Mellon's Center for Cognitive Brain Imaging. The word "celery," for instance, appears most frequently in the corpus with the verb "eat"; often, but less frequently with "taste"; a bit less with "fill," and so forth. Proportionally adding these individual activations together produced the predicted activation pattern for "celery."
To test this idea, the researchers used 58 of the 60 stimulus words to train their computer model and then used the model to predict the activation patterns for the remaining two stimulus words. When they compared the predictions with the actual activation patterns for those two words, the model had a mean accuracy of 77 percent.
The method proved powerful even when predicting activation patterns in semantic areas for which the model was untrained. For example, the model could be retrained with words from all but two of the 12 semantic categories; when tested with nouns such as "airplane" or "celery" from the excluded categories of vehicles and vegetables, the mean accuracy was 70 percent. That wasn't quite as good as when the model was tested with words from the categories the model was trained to handle, but still significantly higher than chance.
To test the model's ability to distinguish among a diverse set of words, they retrained it using 59 of the 60 stimulus words. They then presented the model with the fMRI of the withheld word and a list of 1,000 frequently used words from the corpus, plus the withheld word. The model predicted the fMRI image for all 1,001 words and compared those predictions to the actual fMRI of the withheld word, ranking them in order of similarity. Left to chance, the correct word would score a percentile rank of 0.50; in the research team's model, the mean rank was 0.72. The findings proved powerful enough to merit publication in the May 30, 2008 issue of the journal Science.
"We believe we have identified a number of the basic building blocks that the brain uses to represent meaning," Mitchell says.
Though corpus co-occurrences may not reflect the same methods used by the brain to represent meaning, the study yielded new insights into the nature of human thought. "Before these experiments, nobody knew how meaning would be represented in the brain," Just says. But as he and Mitchell studied the scans, they noted that the voxels that were activated often corresponded with areas of the brain associated with the senses or motor control. That suggests that the biology of the brain drives the way that meanings are stored and represented.
"We are fundamentally perceivers and actors," Just says. "So the brain represents the meaning of a concrete noun in areas of the brain associated with how people sense it or manipulate it. The meaning of an apple, for instance, is represented in brain areas responsible for tasting, for smelling, for chewing. An apple is what you do with it. Our work is a small but important step in breaking the brain's code."
Though the work might someday be useful for so-called "mind reading," Just says it could also provide meaningful tools for analyzing autism and thought disorders such as paranoid schizophrenia. It might also be useful in studying semantic disorders such as Pick's disease, a rare form of dementia with symptoms that can include difficulty in finding words and maintaining a conversation.
Mitchell and Just already are planning to expand their research to include fMRIs for phrases, short sentences, and combinations of words, such as "hungry rabbit" and "running rabbit." Likewise, they want to study how the brain processes abstract concepts such as "democracy," "science," and "justice." Rebecca Hutchinson, a Ph.D. student in computer science who has been working on the neurosemantics project since 2002, is already refining techniques that will help researchers sort out these more complex signals. Researchers will have to deal with uncertainty as to when the activation pattern for one word ends and the pattern for the next word begins. One possible solution is a new class of probabilistic models, called Hidden Process Models, that she and her colleagues developed for analyzing time-series data.
But even for single concrete nouns, "the Science paper is still just a start," says Chang, one of the report's co-authors. The 25 verbs chosen by Mitchell aren't necessarily the optimal set for revealing how the mind encodes meaning; a different set of verbs might work better, or perhaps a larger or even smaller number would be preferable. "Sometimes more is better, but not always," Chang says, noting that too large a set may result in a model that is too specific for a certain subset of subjects and thus limited in its "generalizability"--the ability to make the same predictions using other data sets.
Indra Rustandi, a Ph.D. student in computer science who has worked with Mitchell since 2003, is looking into algorithms that can automatically discover the best representation of the data. For instance, rather than selecting 25 verbs in advance to analyze the corpus, certain algorithms might figure out a set of words that will give the best prediction accuracy. Chang, whose study of semantics is part of his long-term goal to develop a computational model of language processing in the human brain, is also exploring ways to analyze fMRI scans that don't involve corpus co-occurrences. One possibility is based on feature-norming studies in psychology, in which people list the distinguishing characteristics of things. A combination of different semantic layers likely will be necessary to improve prediction accuracy, he says.
For Mitchell, this new insight into the function of the human brain presents an opportunity for computer scientists to reconsider some of their architectures. "One of the main problems in artificial intelligence is (deciding) how robots should represent the myriad things they see in the world," he says.
The human brain could store information about the word "tomatoes" much like a dictionary would, lodging it in the frontal cortex where higher reasoning takes place. Instead, the brain seems to use its sensory and motor sections to store the bulk of this information. Doing so may help the brain operate more efficiently, allowing it to make inferences about what it sees and reason about how to act on that information in the same areas of the brain where perception takes place.
"That's very different than how it's done in robots today," Mitchell says. "Maybe there's a reason the brain does it that way and maybe we should give that a little thought."
About the Photos:
At top, Marcel Just,director of Carnegie Mellon's Center for Cognitive Brain Imaging, and Tom Mitchell, head of the Machine Learning Department.
Second photo: Robert Mason, senior research associate at the Brain Imaging Research Center, a joint project of Carnegie Mellon and the University of Pittsburgh, demonstrates its functional magnetic resonance imaging (fMRI) scanner with the help of research coordinator Justin Abernethy. Using fMRI scans, computer scientist Tom Mitchell and cognitive neuroscientist Marcel Just have developed a model for predicting how different words activate different thought centers in the brain.
Image2:
For More Information:
Jason Togyer | 412-268-8721 | jt3y@cs.cmu.edu